Norvig Web Data Science Award
show what you can do with 3 billion web pages
by ![]() and
and 
show what you can do with 3 billion web pages
by ![]() and
and
By: Feng Wang, Hong Huang & Vincent Gong (Delft University of Technology)
From the submission:
[...] A huge amount of research has been carried out in the past to investigate how to obtain knowledge from text. However, the effectiveness of text-based techniques largely depends on the type of language that the particular piece of text is in. Moreover, the effectiveness of text-based techniques may be jeopardized when the target language is used in an informal way, for instance, when a lot of slang is involved. [...] So we take a different approach: to analyze images, which is kind of a universal format of data. The basic idea is to cluster images in a time period and to get the trends of images in that period in the world. The final outcome should be similar to Google trends, but in image form. We want to use our knowledge and experience of measuring the similarities of images in the context of big data processing.

By: Hannes Mühleise (Database Architecture group at the Centrum Wiskunde & Informatica)
From the submission:
The World Wide Web has (like Sokrates) long been accused of corrupting the youth. These accusations even go so far to claim that the success of the Internet as a whole should be due to easy access to adult entertainment material. With regards to the fraction of Web pages offering this materials, estimates vary widely, alarmists go up to 80%, while more serious research shows something around 4%. [...] The research question of this work is: How great is the percentage of adult entertainment pages on the public WWW, and where do these pages come from.
By: David Huistra & Jelte Zeilstra (University of Twente)
From the submission:
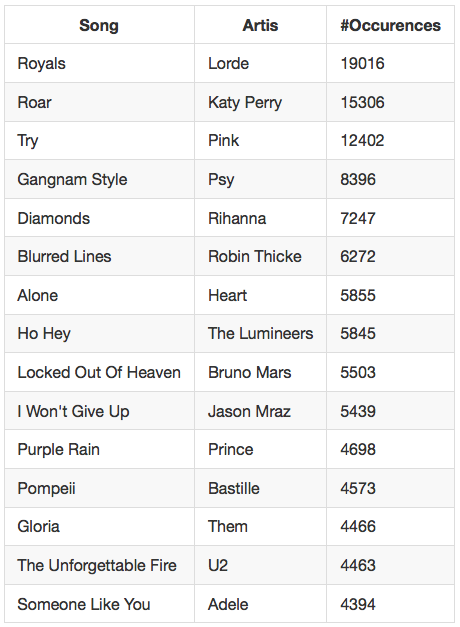
We investigated the possibility of automatically developing lists of popular songs for different countries by detecting song mentionings in the Common Crawl dataset. We found that that it is possible to efficiently determine the country of a web page and that is is possible to efficiently find mentionings of a large number of songs titles (5.7 million) within these web pages. We find however that our current implementation is not sufficient as the amount of false positive song mention detections is too high, but show that on a smaller set of songs, particular the Dutch top2000, the approach produces interesting reshuffeling of this list for different countries.
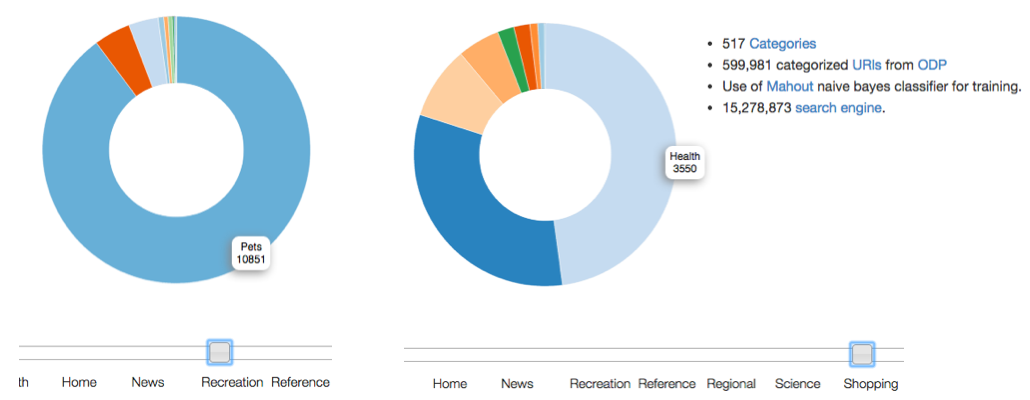
By: P.S.N.Chandrasekaran Ayyanathan, Spyros Foniadakis & Rafik Chelah (Delft University of Technology)
From the submission:
Background for the idea takes its origin from search engines that provide lists of URL's which are the result of web related queries. The user would not have prior knowledge whether the URL truly pertains to what they wish to search and would only be certain of this by manually opening the URL and reading its contents. [...] The idea is to derive all relevant textual data from the common web crawl in order to classify it into different categories and exhibit websites's relativity towards different categories. That insight is strengthened by providing visual representations in form of Scalable Vector Graphics, so as to help the end-user understand the overall picture.